redis之hash
概述
是一个键值对(key-value)集合,它是一个 string 类型的 field 和 value 的映射表
key相当于mysql的表,field相当于mysql的字段名,value相当于mysql的字段值
hash数据结构特别适合存储关系型对象,如:用户信息
使用语法
基本使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
127.0.0.1:6379> hset myhash field1 snailsir #set一个具体key-value
(integer) 1
127.0.0.1:6379> hget myhash field1 #获取一个字段值
"snailsir"
127.0.0.1:6379> hmset myhash field1 hello field2 world #set多个key-value
OK
127.0.0.1:6379> hmget myhash field1 field2 #获取多个字段值
1) "hello"
2) "world"
127.0.0.1:6379> hgetall myhash #获取全部的数据
1) "field1"
2) "hello"
3) "field2"
4) "world"
|
删除指定的key
1
2
3
4
5
|
127.0.0.1:6379> hdel myhash field1
(integer) 1
127.0.0.1:6379> hgetall myhash # 获取所有的字段和值
1) "field2"
2) "world"
|
获取长度
1
2
|
127.0.0.1:6379> hlen myhash
(integer) 1
|
判断某个key是否存在
1
2
3
4
|
127.0.0.1:6379> hexists myhash field1
(integer) 0
127.0.0.1:6379> hexists myhash field2
(integer) 1
|
只获取key或value
1
2
3
4
|
127.0.0.1:6379> hkeys myhash
1) "field2"
127.0.0.1:6379> hvals myhash
1) "world"
|
字段自增
1
2
3
4
5
6
|
127.0.0.1:6379> hset myhash field3 5
(integer) 1
127.0.0.1:6379> hincrby myhash field3 1
(integer) 6
127.0.0.1:6379> hincrby myhash field3 -1
(integer) 5
|
不存在设置,存在则不能设置
1
2
3
4
|
127.0.0.1:6379> hsetnx myhash field4 hello
(integer) 1
127.0.0.1:6379>hsetnx myhash field4 world
(integer) 0
|
应用场景
购物车
对象存储
string vs hash
|
string+json |
Hash |
| 效率 |
很高 |
高 |
| 容量 |
低 |
低 |
| 灵活性 |
低 |
高 |
| 序列化 |
简单 |
复杂 |
当对象的某个属性需要频繁修改时,不适合用string+json,因为它不够灵活,每次修改都需要重新将整个对象序列化并赋值,如果使用hash类型,则可以针对某个属性单独修改,没有序列化,也不需要修改整个对象。比如,商品的价格、销量、关注数、评价数等可能经常发生变化的属性,就适合存储在hash类型里。
数据结构
底层实现:压缩列表+hash表(字典)实现
存储的值小于64字节使用压缩列表来存储,否则使用hash表来存储
字典
又称符号表,关联数组或者映射,是一种用于保存键值对的抽象数据结构
字典中的每个键都是独一无二的,程序可以在字典中根据键值查找与之关联的值,或通过键来更新值,删除等
c语言是没有字典的
字典结构
1
2
3
4
5
6
7
|
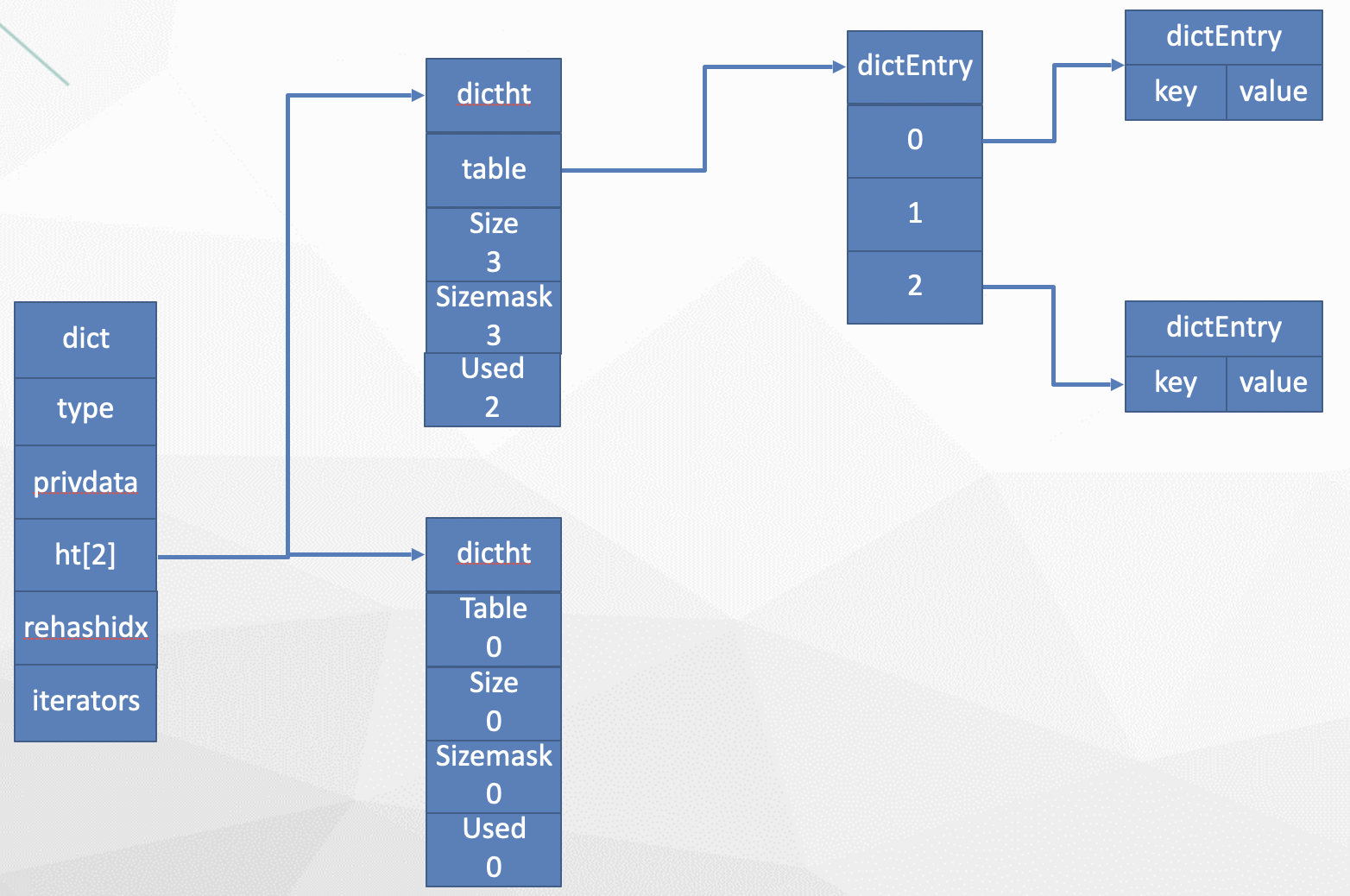
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx;
unsigned long iterators;
} dict;
|
- type属性是一个指向dictType结构的指针,每个dictType用于操作特定类型键值对的函数,Redis会为用途不同的字典设置不同的类型特定函数。
- privdata属性则保存了需要传给给那些类型特定函数的可选参数。
- ht[2]: hash表,只会维护ht[0]与ht[1] (因为重新散 列的原因),数据会存储在这里
- rehashidx :重新散列进度,0:开始 -1:结束
重新散列为了进行hash表的扩容
重新散列流程:
- 当ht[0]的容量(2^32)到一定程度时,这个时候我们在执行新增数据、修改、删除数据的时候,就会触发重新散列
- 当新增数据的时候,会把数据插入到ht[1]中,修改数据时,也会把修改后的数据更新到ht[1]中,删除会把ht[0]中的数据删除
- ht[1]的容量是ht[0]容量的n次幂
- 散列过程中,ht[0]与ht[1]是同时存在的
hash表
1
2
3
4
5
6
7
|
typedef struct dictht
{
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
|
- table属性是一个数组,数组中的每个元素都是一个指向dict.h/dictEntry结构的指针,每个dictEntry结构保存着一个键值对
- size属性记录了哈希表的大小,也是table数组的大小
- used属性则记录哈希表目前已有节点(键值对)的数量
- sizemask属性的值总是等于 size-1(从0开始),这个属性和哈希值一起决定一个键应该被放到table数组的哪个索引上面(索引下标值)。
https://www.cnblogs.com/coloz/p/13812850.html
https://www.cnblogs.com/qhhfRA/p/18523819
hash节点
1
2
3
4
5
6
7
8
9
10
|
typedef struct dictEntry
{
void *key;
union{
void *val;
uint64_tu64;
int64_ts64;
} v;
struct dictEntry *next;
} dictEntry;
|
字典总体结构