redis之list
概述
用来存储多个有序的字符串的,列表当中的每一个字符看做一个元素,一个列表当中可以存储一个或多个元素。
redis的list支持存储2^32-1的元素,是一种比较灵活的链表格式,可以充当队列或者栈的角色。redis的list可以从列表的两端插入(pubsh)和弹出(pop)元素。
redis列表是链表型的数据结构,所以它的元素是有序的,而且列表内的元素是可以重复的。意味着它可以根据链表的下标获取指定的元素和某个范围内的元素集。
使用语法
添加
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
127.0.0.1:6379> lpush list one two #将一个值或多个值,插入到列表的头部(左)
(integer) 2
127.0.0.1:6379> lpush list three
(integer) 3
127.0.0.1:6379> lrange list 0 -1 #通过区间获取具体的值
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> lrange list 0 1
1) "three"
2) "two"
127.0.0.1:6379> rpush list four #将一个值或多个值,插入到列表的尾部(右)
(integer) 4
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "two"
3) "one"
4) "four"
|
删除
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
127.0.0.1:6379> lpop list #移除列表的第一个值
"three"
127.0.0.1:6379> rpop list #移除列表的最后一个值
"four"
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
# redis的list是链表结构所以BLPOP命令正是取出列表的第一个元素,如果list当中没有没有元素,会一直等待到超时,或者发现有数据为止
127.0.0.1:6379> blpop ranking 10
1) "ranking"
2) "redis"
127.0.0.1:6379> blpop ranking 10
1) "ranking"
2) "mysql"
127.0.0.1:6379> blpop ranking 10
(nil)
(10.08s)
127.0.0.1:6379>
|
操作下标
1
2
|
127.0.0.1:6379> lindex list 1
"one"
|
列表的长度
1
2
|
127.0.0.1:6379> llen list #返回列表的长度
(integer) 2
|
移除指定的值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
127.0.0.1:6379> lrange list 0 -1
1) "one"
2) "two"
3) "one"
4) "two"
5) "one"
6) "three"
7) "two"
127.0.0.1:6379> lrem list 1 two #移除1个two
(integer) 1
127.0.0.1:6379> lrange list 0 -1
1) "one"
2) "one"
3) "two"
4) "one"
5) "three"
6) "two"
127.0.0.1:6379> lrem list 2 one #移除2个one
(integer) 2
|
list 截取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
127.0.0.1:6379> lpush mylist l1
(integer) 1
127.0.0.1:6379> lpush mylist l2
(integer) 2
127.0.0.1:6379> lpush mylist l3
(integer) 3
127.0.0.1:6379> lpush mylist l4
(integer) 4
127.0.0.1:6379> lpush mylist l5
(integer) 5
127.0.0.1:6379> lpush mylist l6
(integer) 6
127.0.0.1:6379> lpush mylist l7
(integer) 7
127.0.0.1:6379> ltrim mylist 2 4 #通过下标截取,这个list已经被改变了,剩下的元素为下标[2,4]的元素!
OK
127.0.0.1:6379> lrange mylist 0 -1
1) "15"
2) "14"
3) "13"
|
移除最后一个元素并添加的新的列表中
1
2
3
4
5
6
7
8
9
10
11
12
13
|
127.0.0.1:6379> rpush mylist hello
(integer) 1
127.0.0.1:6379> rpush mylist hello1
(integer) 2
127.0.0.1:6379> rpush mylist hello12
(integer) 3
127.0.0.1:6379> rpoplpush mylist myotherlist
"hello12"
127.0.0.1:6379> lrange mylist 0 -1
1) "hello"
2) "hello1"
127.0.0.1:6379> lrange myotherlist 0 -1
1) "hello12"
|
按下标更新元素
1
2
3
4
5
6
7
8
9
10
|
127.0.0.1:6379> lset list 0 val #如果不存在列表我们去更新就会报错
(error) ERR no such key
127.0.0.1:6379> lpush list value1
(integer) 1
127.0.0.1:6379> lrange list 0 0
1) "value1"
127.0.0.1:6379> lset list 0 newvalue1 #如果存在,更新当前下标的值
OK
127.0.0.1:6379> lrange list 0 -1
1) "newvalue1"
|
将某个具体的value插入到某个元素的前面或后面!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
127.0.0.1:6379> rpush mylist hello
(integer) 1
127.0.0.1:6379> rpush mylist world
(integer) 2
127.0.0.1:6379> linsert mylist before "world" "other"
(integer) 3
127.0.0.1:6379> lrange mylist 0 -1
1) "hello"
2) "other"
3) "world"
127.0.0.1:6379> linsert mylist after "world" "new"
(integer) 4
127.0.0.1:6379> lrange mylist 0 -1
1) "hello"
2) "other"
3) "world"
4) "new"
|
小结
它实际上是一个链表,before node after, left ,right都可以插入值
如果key不存在,创建新的链表
如果key存在,新增内容
如果移除了所有的值,空链表,也代表不存在!
在两边插入活改动值,效率最高!中间元素,相对来说效率会低一点
应用场景
秒杀抢购
为了解决秒杀的问题:超卖、高并发、恶意请求
排行榜
zset更合适
分页
数据结构
list类型结构实现主要依据是:链表与压缩列表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
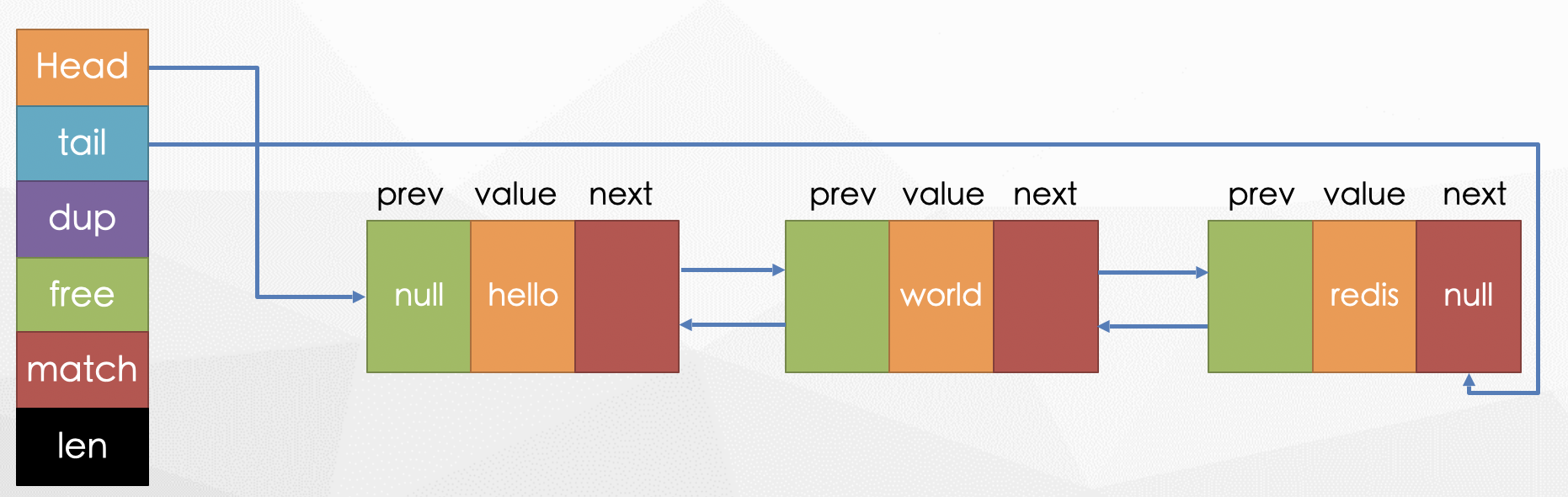
typdef struct listNode{
struct listNode *prev; // 前指针,指向前面的节点
struct listNode *next; // 后指针,指向后面的节点
void *value; // 当前节点的值
} listNode;
typedef struct listIter{
listNode *next; // 指向下一个结点的指针
int direction; // 迭代方向,从前往后或从后往前
} listIter;
typedef struct list{
listNode *head; // 头节点指针
listNode *tail; // 尾节点指针
void *(*dup)(void *ptr); // 复制函数指针
void (*free)(void *ptr); // 释放函数指针
void (*match)(void *ptr,void *key); // 匹配函数指针
unsigned long len; // 链表长度
} list;
|
链表
压缩列表

- Zlbytes:压缩列表占用的内存字节数
- Zltail:压缩列表尾结点距离起始地址有多少字节
- Zllen:压缩列表节点数
- entryX:压缩列表节点
- Zlend:压缩列表末端

- Previous_entry_length:压缩列表前一个节点的长度
- Encoding:当前节点的值的类型与长度
- Content:当前节点的值
压缩列表的遍历(表尾遍历到表头)

我们可以通过命令来查看,某个list使用的是哪种数据结构存储的数据
1
2
3
4
|
127.0.0.1:6379> rpush listKey e1 e2 e3
(integer) 3
127.0.0.1:6379> object encoding listKey # 查看使用的是哪种数据结构存储的数据
"quicklist"
|
redis中的列表对象在版本3.2之前,列表底层的编码是ziplist和linkedlist实现的,但是在版本3.2-6之后,重新引入了一个quicklist的数据结构,列表的底层都由quicklist实现
quicklist本质是一个双向链表,链表的节点类型是ziplist,当ziplist节点过多,quicklist会退化成双向链表,以提高效率。
1
2
3
4
5
6
7
8
9
10
11
12
|
typedef struct quicklistNode{
struct quicklistNode *prev; // 指向前驱节点
struct quicklistNode *next; // 指向后继结点
unsigned char *zl; // 指向对应的压缩列表
unsigned int sz; // 压缩列列表的大小
unsigned int count : 16;
unsigned int encoding : 2; // 采用的编码方式,1:原生,2代表使用LZF进行压缩
unsigned int container : 2; // 为节点指向的容器类型,1:none 2:ziplist存储数据
unsigned int recompress : 1; // 代表这个节点是否是压缩节点,如果是,则使用压缩节点前先进行解压缩,使用后重新压缩
unsigned int attempted_compress : 1; // 测试时使用
unsigned int extra : 10;
} quicklistNode;
|
