适者生存!一定要逼着自己学习,这是在这个社会生存的唯一法则!
nosql概述
为什么要用nosql
大数据时代:一般的数据库无法进行分析处理了!
1、单机mysql的年代

90年代,一个基本的网站访问量一般不会太大,单个数据库完全足够!那个时候,更多的去使用静态网页 html~ 服务器根本没有太大的压力!
思考一下,这种情况下:整个网站的瓶颈是什么?
1、数据量太大、一个机器放不下了!
2、数据的索引(B+Tree),一个机器内存也放不下
3、访问量(读写混合),一个服务器承受不了了
只要你开始出现以上的三种情况之一,那么你就必须要晋级!
2、Memcached(缓存) +mysql + 垂直拆分(读写分离)
网站80%的情况下都是在读,每次都要去查询数据库的话就十分的麻烦!所以我们希望减轻服务器的压力,我们可以使用缓存来保证效率
发展过程:优化数据结构和索引 -> 文件缓存(IO) ->Memcached(当时最热门的技术!)
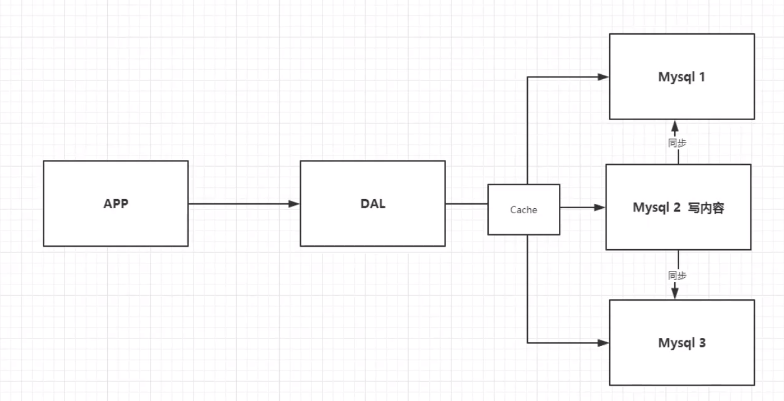
3、分库分表 + 水平拆分 + mysql集群
技术和业务在发展的同时,对人的要求也越来越高!
本质:数据库(读,写)
mysql引擎:
MyISAM:表锁,十分影响效率!高并发下就会出现严重的锁问题!
Innodb:行锁
慢慢的就开始使用分库分表来解决写得压力!Mysql在哪个年代推出了表分区
MySQL的集群,很好满足那个年代的所有需求!
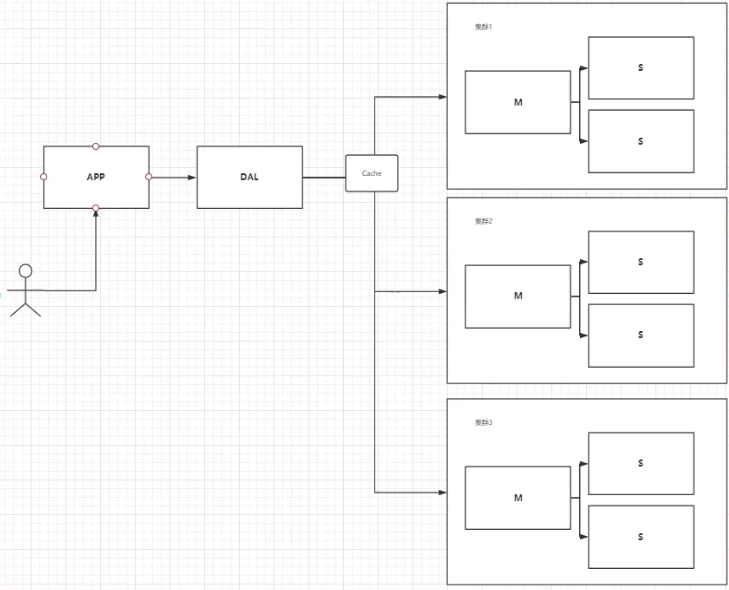
4、如今最近的年代
2010–2020 十年之间,世界已经发生了翻天覆地的变化。
MySQL等关系型数据库就不够用了!数据量很多,变化很快!
MySQL使用它来存储一些比较打的文件,博客,图片!数据库表很大,效率很低!如果有一种数据库来专门处理这种数据 MySQL的压力就变得十分小(研究如何解决这些问题)大数据I0压力下,表几乎没法更大!
目前一个互联网公司
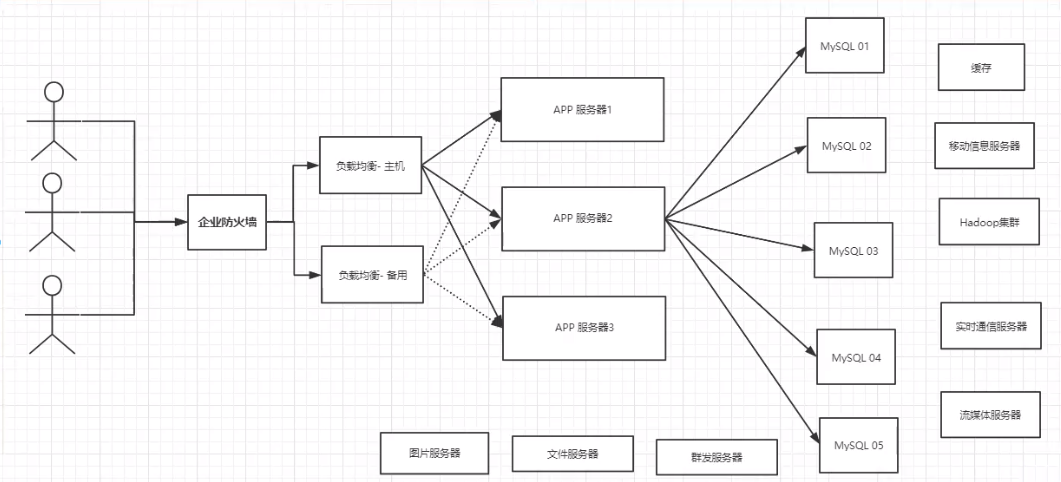
为什么要用NoSQL!
用户 个人信息,社交网络,地理位置。用户自己产生的数据,用户日志等等爆发式增长!
这时候我们就需要使用NoSQL数据库,NoSQL可以很好的处理以上的问题!
什么是nosql
NoSql = not only sql (不仅仅是sql) 泛指非关系型数据库
关系型数据库: 表格,行,列
随着web2.0 互联网的诞生!传统的关系型数据库很难对付web2.0时代!尤其是超大规模的高并发的社区!暴露出来很多难以克服的问题,NoSQL在当今大数据环境下发展的十分迅速,Redis是发展最快的,而且是我们当下必须要掌握的一个技术!
很多的数据类型,用户的个人信息,社交网络,地理位置。这些数据类型的存储不需要一个固定的格式!不需要多余的操作就可以横向扩展的!
nosql特点
1、方便拓展(数据之间没有关系,很多拓展!)
2、大数据量,高性能(Redis 1s可以写8W次,读取11W,nosql的缓存,记录级的,是一种细粒度的缓存,性能会比较高!)
3、数据类型是多样型的!(不需要事先设计数据库!随取随用!如果是数据量十分大的表,很多人就无法设计了!)
传统的RDBMS 和 Nosql的区别
传统的RDBMS
结构化组织
sql
数据和关系都存在单独的表中
严格的一致性
基础的事务
NOSQL
不仅仅是数据
没有固定的查询语言
键值对存储,列存储,文档存储,图形数据库(社交关系)
最终一致性
CAP定理和BASE (异地多活) 初级架构师!
高可用,高性能,高可拓
了解3V+3高
大数据时代的3V: 主要是描述问题的
1、海量Volume
2、多样Variety
3、实时Velocity
大数据时代的3高:主要是对程序的要求
1、高并发
2、高可拓
3、高性能
真正在公司中的实践:NoSQL+RDBMS一起使用才是最强的。
技术没有高低之分,就看你如何使用(思维的提高!)
nosql的四大分类
kv键值对
- 新浪:redis
- 美团:redis+tail
- 阿里、百度:redis+memecache
文档型数据库(bson格式和json一样)
列存储的数据库
图关系数据库
- 它不是存储图片的,放的是关系,比如:朋友社交网络,广告推荐!
- Neo4j
Redis入门
redis是什么?
redis(Remote Dictionary Server),即远程字典服务。是一个开源的使用C语言编写、支持网络、可基于内存亦可持久化的日志型、key-value数据库,并提供多种语言的api。
因为值(value)可以是 字符串(String), 哈希(Hash), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型,也被人们称为结构化数据库!
redis能干什么?
1、内存存储、持久化,内存中是断电即失的,所以持久话很重要(rdb、dof)
2、效率高,可以用于高速缓存
3、发布订阅系统
4、地图信息分析
5、计时器、计数器(浏览量!)
特性
1、多样的数据类型,不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
2、持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用
3、集群
4、事务
安装
linux安装
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# 1、下载安装包!
# 2、解压redis的安装包! 程序都放到/opt目录下
[root@snailsir home]# mv redis-5.0.8.tar.gz /opt
[root@snailsir home]# cd /opt
[root@snailsir opt]# tar -zxvf redis-5.0.8.tar.gz
# 3、基本的环境安装
yum install gcc-c++
# 4、安装
cd redis-5.0.8
make
make install
# 5、复制配置文件
cp /opt/redis-5.0.8/redis.conf /usr/local/bin/redis
# 6、启动redis
redis-server /usr/local/bin/redis/redis.conf
|
问题
安装6.0 出错
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
server.c:5151:94: error: 'struct redisServer' has no member named 'unixsocket'
serverLog(LL_NOTICE,"The server is now ready to accept connections at %s", server.unixsocket);
^
server.c:5152:19: error: 'struct redisServer' has no member named 'supervised_mode'
if (server.supervised_mode == SUPERVISED_SYSTEMD) {
^
server.c:5153:24: error: 'struct redisServer'' has no member named 'masterhost'
if (!server.masterhost) {
^
server.c:5166:15: error: 'struct redisServer' has no member named 'maxmemory'
if (server.maxmemory > 0 && server.maxmemory < 1024*1024) {
^
server.c:5166:39: error: 'struct redisServer' has no member named 'maxmemory'
if (server.maxmemory > 0 && server.maxmemory < 1024*1024) {
^
server.c:5167:176: error: 'struct redisServer' has no member named 'maxmemory'
serverLog(LL_WARNING,"WARNING: You specified a maxmemory value that is less than 1MB (current value is %llu bytes). Are you sure this is what you really want?", server.maxmemory);
^
server.c:5170:31: error: 'struct redisServer' has no member named 'server_cpulist'
redisSetCpuAffinity(server.server_cpulist);
|
错误原因:
gcc版本问题,新版本的。redis6.0以上
解决办法
1
2
3
4
5
6
7
8
9
|
#升级到 5.3及以上版本
yum -y install centos-release-scl
yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
scl enable devtoolset-9 bash
#注意:scl命令启用只是临时的,推出xshell或者重启就会恢复到原来的gcc版本。
#如果要长期生效的话,执行如下:
echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile
|
性能测试
redis-benchmark是一个压力测试工具!
官方自定的性能测试工具!
redis-benchmark命令参数:
redis 性能测试工具可选参数如下所示:
| 序号 |
选项 |
描述 |
默认值 |
| 1 |
-h |
指定服务器主机名 |
127.0.0.1 |
| 2 |
-p |
指定服务器端口 |
6379 |
| 3 |
-s |
指定服务器 socket |
|
| 4 |
-c |
指定并发连接数 |
50 |
| 5 |
-n |
指定请求数 |
10000 |
| 6 |
-d |
以字节的形式指定 SET/GET 值的数据大小 |
2 |
| 7 |
-k |
1=keep alive 0=reconnect |
1 |
| 8 |
-r |
SET/GET/INCR 使用随机 key, SADD 使用随机值 |
|
| 9 |
-P |
通过管道传输 请求 |
1 |
| 10 |
-q |
强制退出 redis。仅显示 query/sec 值 |
|
| 11 |
–csv |
以 CSV 格式输出 |
|
| 12 |
-l |
生成循环,永久执行测试 |
|
| 13 |
-t |
仅运行以逗号分隔的测试命令列表。 |
|
| 14 |
-I |
Idle 模式。仅打开 N 个 idle 连接并等待。 |
|
我们来简单测试下:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#测试 100个并发连接, 每个并发100000请求
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
#********* set *********#
100000 requests completed in 1.68 seconds # 对我们的10w个请求进行写入测试
100 parallel clients # 100个并发客户端
3 bytes payload # 每次写入3个字节
keep alive: 1 # 只有一台服务器来处理这些请求,单机性能
29.03% <= 1 milliseconds
99.90% <= 2 milliseconds
100.00% <= 2 milliseconds # 所有请求在3毫秒处理完成
59382.42 requests per second # 每秒处理59382.42次请求
|
redis的基础知识
redis默认有16个数据库,可以通过配置文件配置
默认使用的是第0个
可以使用select进行切换数据库
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
# 设置过期时间 毫秒# 重命名key
rename old_key new_key # 如何new_key存在的话,old_key的值会覆盖new_key值
renamenx old_key new_key # 不会覆盖,存在返回0,不存在返回1127.0.0.1:6379> select 3 #切换数据库
OK
127.0.0.1:6379[3]> DBSIZE #查看DB大小
(integer) 0
127.0.0.1:6379> keys * #查看所有key
1) "mylist"
# 匹配[]内某个字符
keys sit[ey] # 可以匹配 site或sity
# 匹配单个字符
keys si?e
# 随机返回一个key
randomkey
# 删除一个key
del keyname
# 重命名key
rename old_key new_key # 如何new_key存在的话,old_key的值会覆盖new_key值
renamenx old_key new_key # 不会覆盖,存在返回0,不存在返回1
# set key
set name snailsir
#查看当前key的类型
type name
#判断当前key是否存在
exists name
#将name的key从当前空间移动到1空间内
move name 1
#设置key过期时间,单位是s
expire name 10
#查看当前key的剩余时间,单位s
ttl name
# 设置过期时间 毫秒
pexpire key 9000
# 查看生命周期剩余时间,毫秒
pttl key
#清除当前数据库
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> keys *
(empty list or set)
#清空所有数据库
127.0.0.1:6379> flushall
OK
|
redis是单线程的
明白redis是很快的,官方表示,redis是基于内存操作,CPU不是redis性能瓶颈,Redis的瓶颈是根据机器的内存和网络带宽,既然可以使用单线层来实现,就使用单线程了!
为什么redis单线程还这么快?
1、误区1:高性能的服务器一定是多线程的?
2、误区2:多线程(CPU上下文会切换!)一定比单线程效率高! cpu>内存>硬盘的速度
核心:redis是将所有的数据全部放在内存中的,所以说使用单线程去操作效率就是最高的,多线程(CPU上下文切换:耗时的操作!),对于内存系统来说,如果没有上下文切换效率就是最高的!多次读写都是在一个CPU上的,在内存情况下,这个就是最佳方案!
redis五大数据类型
特殊数据类型
geospetial 地理位置
朋友的定位,附近的人,打车距离计算?
Redis 的 Geo 这个功能可以推算地理位置的信息,两地之间的距离,方圆几里的人
可以查询一些测试数据:http://www.jsons.cn/lngcodeinfo/0706D99C19A781A3
官方文档: https://www.redis.net.cn/order/3685.html
geoadd 添加地理位置
1
2
3
4
5
6
7
8
9
10
11
12
|
#规则:两极无法直接添加,我们一般会下载城市数据,直接通过程序一次性导入!
#参数 key 值(维度 经度 名称)
127.0.0.1:6379> geoadd china:city 116.40 39.90 beijing
(integer) 1
127.0.0.1:6379> geoadd china:city 121.47 31.23 shanghai 106.50 29.53 chongqing 115.05 22.52 shenzhen 120.15 30.28 hangzou 125.14 42.92 xian
(integer) 5
#有效的经度从-180度到180度。
#有效的纬度从-85.05112878度到85.05112878度。
#当坐标位置超出上述指定范围时,该命令将会返回一个错误
127.0.0.1:6379> geoadd china:city 39.90 116.40 beijing
(error) ERR invalid longitude,latitude pair 39.900000,116.400000
|
geopos 获取指定城市的经度和维度
1
2
3
4
5
|
127.0.0.1:6379> geopos china:city beijing chongqing
1) 1) "116.39999896287918091"
2) "39.90000009167092543"
2) 1) "106.49999767541885376"
2) "29.52999957900659211"
|
geodist 两人经纬度的直线距离
单位:
1
2
3
4
|
127.0.0.1:6379> geodist china:city beijing shanghai #默认是米
"1067378.7564"
127.0.0.1:6379> geodist china:city beijing shanghai km
"1067.3788"
|
georadius 以给定的经纬度为中心,找出某一半径内的元素
我附近的人?(获得所有附近的人的地址,定位!)通过半径来查询!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
127.0.0.1:6379> georadius china:city 110 30 1000 km #以100 30这个经纬度为中心,寻找方圆1000km内的城市
1) "chongqing"
2) "shenzhen"
3) "hangzou"
127.0.0.1:6379> georadius china:city 110 30 500 km
1) "chongqing"
127.0.0.1:6379> georadius china:city 110 30 500 km withdist #显示到中心距离的位置
1) 1) "chongqing"
2) "341.9374"
127.0.0.1:6379> georadius china:city 110 30 500 km withcoord #显示他人的定位信息
1) 1) "chongqing"
2) 1) "106.49999767541885376"
2) "29.52999957900659211"
127.0.0.1:6379> georadius china:city 110 30 500 km withcoord count 1 #筛选出指定的结果
1) 1) "chongqing"
2) 1) "106.49999767541885376"
2) "29.52999957900659211"
|
georadiusbymember 找出位于指定元素周围的其他元素
1
2
3
4
5
6
|
127.0.0.1:6379> georadiusbymember china:city beijing 1000 km
1) "beijing"
2) "xian"
127.0.0.1:6379> georadiusbymember china:city shanghai 400 km
1) "hangzou"
2) "shanghai"
|
geohash 返回一个或多个位置元素的getohash表示
该命令将返回11个字符的geohash字符串!
1
2
3
4
|
# 将二维的经纬度转换为一维的字符串,如果两个字符串越接近,那么则越近
127.0.0.1:6379> geohash china:city beijing chongqing
1) "wx4fbxxfke0"
2) "wm5xzrybty0"
|
geo 底层的实现原理其实就是zset! 我们可以使用zset命令来操作geo!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
127.0.0.1:6379> zrange china:city 0 -1 #查看地图中全部元素
1) "chongqing"
2) "shenzhen"
3) "hangzou"
4) "shanghai"
5) "beijing"
6) "xian"
127.0.0.1:6379> zrem china:city beijing #移除指定元素
(integer) 1
127.0.0.1:6379> zrange china:city 0 -1
1) "chongqing"
2) "shenzhen"
3) "hangzou"
4) "shanghai"
5) "xian"
|
Hyperloglog
基数:不重复的元素,可以接受误差!
Hyperloglog 用来做基数统计的算法!
网页的uv(一个人访问一个网站多次,但是还是算做一个人)
传统方式:set保存用户的id,然后就可以统计set中的元素数量作为标准判断!
这种方式如果保存大量的用户id,就会比较麻烦!我们的目的是为了计数,而不是保存用户id;
优点:
占用内存是固定的,2^64不同的元素的基数,只需要12kb内存!如果要从内存角度来比较的话,hyperloglog是我们首选。
0.81%错误率!统计uv任务,可以忽略不计的!
1
2
3
4
5
6
7
8
9
10
11
12
|
127.0.0.1:6379> pfadd mykey a b c d e f g h i j #创建第一组元素
(integer) 1
127.0.0.1:6379> pfcount mykey #统计mykey元素的基数数量
(integer) 10
127.0.0.1:6379> pfadd mykey2 i j z x c v b n m #创建第二组元素 mykey2
(integer) 1
127.0.0.1:6379> pfcount mykey2
(integer) 9
127.0.0.1:6379> pfmerge mykey3 mykey mykey2 #合并两组 mykey mykey2 =》 mykey3 并集
OK
127.0.0.1:6379> pfcount mykey3 #查看并集数量
(integer) 15
|
如果允许容错,那么一定可以使用Hyperloglog
如果不允许容错,就使用set或者自己的数据类型即可!
bitmap
位存储(两个状态)操作二进制位来记录,就只有0和1两个状态!
统计疫情感染人数: 0 0 0 1 0
统计用户信息,活跃,不活跃
登录、未登录
打卡 365天 365bit
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# 记录周一到周末的打卡
127.0.0.1:6379> setbit sign 0 1 #周一打卡
(integer) 0
127.0.0.1:6379> setbit sign 1 0 #周二未打卡
(integer) 0
127.0.0.1:6379> setbit sign 2 0
(integer) 0
127.0.0.1:6379> setbit sign 3 1
(integer) 0
127.0.0.1:6379> setbit sign 4 1
(integer) 0
127.0.0.1:6379> setbit sign 5 0
(integer) 0
127.0.0.1:6379> setbit sign 6 0
(integer) 0
127.0.0.1:6379> getbit sign 6 # 查看星期天是否打卡
(integer) 0
127.0.0.1:6379> bitcount sign #统计这周打卡天数,就可以看是否全勤
(integer) 3
|
